La Estadística en tiempos de incertidumbre, de la COVID-19, el Big Data y la Inteligencia Artificial
20 mayo, 2020
En momentos de crisis económica, como el actual, es muy importante reducir la incertidumbre para crear marcos de confianza que ayuden a la recuperación económica. La fuente principal de incertidumbre en estos momentos es el comportamiento del SARS-CoV-2 y la evolución de la COVID-19. Son muchas las áreas de conocimiento que están trabajando intensamente para conocer mejor este comportamiento y esta evolución. Entre ellas, la Estadística.
Uno de los peores enemigos que tiene la economía en estos momentos, para tratar de salir de la grave crisis en que nos encontramos, es la incertidumbre. La incertidumbre afecta la actividad económica y la toma de decisiones de muy diversas maneras. Así por ejemplo, en situaciones de gran incertidumbre las empresas retrasan la inversión y la contratación, los costes de financiación aumentan al incrementarse las primas de riesgo, y además los hogares reducen el gasto en previsión de posibles cambios en sus ingresos. Estas contracciones en las inversiones y en el consumo afectan directamente al crecimiento económico, y muy especialmente en el mercado de trabajo.
Y de este claro efecto de la incertidumbre sobre la economía tenemos algunos ejemplos muy recientes. Según el Fondo Monetario Internacional (FMI), la incertidumbre sobre la política fiscal, reguladora y monetaria de Estados Unidos y de la Unión Europea contribuyó de forma clara tanto en la caída económica del período 2008-2009 como en las lentas recuperaciones de los períodos siguientes. Durante aquella crisis financiera la mayor caída trimestral del PIB en España fue del 2,6% (primer trimestre de 2009). Ahora, con la crisis del coronavirus, la economía española ha caído el primer trimestre de 2020 el doble (un 5,2%), la mayor caída en casi un siglo. Estamos, por tanto, ante una crisis muy grande y si aprendemos de lecciones pasadas, tendremos que tener muy en cuenta que una reducción significativa de la incertidumbre puede ayudar de forma decidida a encontrar el camino hacia una más rápida recuperación económica.
Big Data e Inteligencia artificial para reducir la incertidumbre
Desde el punto de vista económico, la incertidumbre se refiere a cómo los diferentes agentes económicos, muy especialmente empresas y consumidores, no tienen ninguna seguridad sobre las perspectivas futuras de la economía. Y en estos momentos, estas perspectivas futuras dependen muy claramente de la evolución de la COVID-19 y del descubrimiento de una vacuna que permita volver a lo que se ha ido llamando «nueva normalidad». A pesar de que se está trabajando muy intensamente en todo el mundo (en estos momentos se están haciendo más de 400 ensayos clínicos, con algunos resultados positivos en tratamientos antivirales y con pruebas esperanzadoras en humanos de posibles vacunas), aunque hay un desconocimiento muy grande sobre la enfermedad y su comportamiento. Aunque los diferentes planes de desconfinamiento que se diseñan intentan reducir algunas incertidumbres, con diferentes medidas preventivas, para tratar de crear un marco de confianza tanto para las empresas como para los consumidores, realmente todavía hay muchas incógnitas que son difíciles de descubrir.
Desde diferentes áreas de conocimiento se está trabajando muy intensamente para ayudar a reducir la incertidumbre, con la elaboración de artículos científicos para explicar qué está pasando y para probar prever por dónde pueden ir las cosas. Un buen ejemplo de esta gran actividad científica es el corpus de trabajos de investigación sobre COVID-19 que mantiene actualizado el Allen Institute for Artificial Intelligence, y que ya contiene alrededor de las 60.000 referencias. El volumen de trabajos es tan elevado que en marzo pasado la Office of Science and Technology Policy del gobierno de Estados Unidos hizo un llamamiento a la comunidad científica internacional de Inteligencia Artificial para el desarrollo de técnicas de procesamiento de lenguaje natural y minería de textos que ayudaran a «navegar» por este corpus y facilitaran los médicos y científicos dar respuesta a las preguntas que la comunidad científica se está haciendo sobre la COVID-19. Muchas de estas preguntas están recogidas en la plataforma Kaggle, una conocida plataforma en el mundo de la Ciencia de datos y de Inteligencia Artificial.
Y es que en plena era del Big Data, la Inteligencia Artificial es una de las áreas de conocimiento que más está trabajando para conocer el desarrollo de la enfermedad y para hacer predicciones futuras que ayuden a reducir muchas de las incertidumbres que tenemos. Y también es una de las que mejores resultados está obteniendo. De hecho, fue BlueDot, una plataforma de monitorización de salud para Inteligencia Artificial, una de las primeras voces que alertó sobre casos de neumonía no identificada en la ciudad china de Wuhan, a finales de diciembre de 2019, semanas antes de que la misma Organización Mundial de la Salud (OMS) declarara la alerta sanitaria global. Además, el mismo sistema también fue capaz de pronosticar de forma correcta los puestos de fuera de China donde llegaría primero el coronavirus (Bangkok, Seúl, Taipei y Tokio).

La falta de datos fiables
De todos modos, en la actual crisis del coronavirus, la Inteligencia Artificial tiene dos limitaciones importantes para poder ser aún de más utilidad: necesita enormes cantidades de datos (Big Data) para funcionar, y además requiere que estos datos procedan (evidentemente) de fuentes de información fiables. Cuántas personas hay realmente con la COVID-19? ¿Cuántas personas han tenido ciertamente la COVID -19 y se han recuperado? Cuántos muertos hay verdaderamente por causa de la COVID -19? ¿Qué datos hay disponibles sobre estas personas? ¿Conocemos exactamente su geolocalización? ¿Sabemos de forma veraz qué contactos directos de las personas diagnosticadas han sufrido la enfermedad y cuáles no? ¿Conocemos efectivamente todas las características individuales de los enfermos para COVID -19?
Estas preguntas son sólo una muestra de la información que se necesita conocer, de forma fiable, para analizar adecuadamente la situación en que nos encontramos e intentar prever posibles escenarios de futuro. La imposibilidad de hacer pruebas PCR masivas, la existencia de diferentes protocolos a la hora de contabilizar casos ya la hora de registrar las muertes o las dificultades para compartir, en tiempo real, datos de personas respetando su privacidad, son sólo algunas de las causas que hacen que sea muy complicado disponer de datos masivas ya la vez fiables. Y en este contexto, la Inteligencia Artificial no puede desplegar todo su potencial para tratar de reducir la percepción de incertidumbre de forma efectiva. Sin embargo, hay muchas iniciativas que buscan encontrar una solución a estos problemas fomentando la coordinación internacional entre expertos en esta área de conocimiento. De entre estas iniciativas, se puede destacar el grupo de trabajo CoronaWhy, donde más de 900 voluntarios expertos en Inteligencia Artificial tienen como objetivo, precisamente, mejorar la coordinación y el análisis global de todos los datos disponibles y relevantes por el brote de la Covidien-19, y también asegurarse de que todos los hallazgos lleguen a quien las pueda necesitar. Pero de todos modos, no es suficiente.
Ante las dificultades de obtener grandes volúmenes de datos fiables, hay un área de conocimiento que está aportando soluciones a este problema, y está haciendo una importante contribución a la hora de analizar de forma rigurosa la situación en que nos encontramos. ¿Qué pasa cuando no tenemos información de toda la población? ¿Qué podemos hacer cuando no se puede acceder a todos los individuos que queremos estudiar? ¿Como nos lo hacíamos antes de entrar en la era del Big Data? La respuesta a esta última pregunta es muy sencilla: buscábamos una muestra de la población que fuera la más representativa posible, con un tamaño suficiente para tener unos márgenes de error pequeños, y entonces mirábamos de inferir a toda la población los resultados obtenidos por a esta muestra. El área de conocimiento que trata esta metodología cuantitativa de análisis es la Estadística.
La formación en Estadística sigue siendo útil y necesaria
La formación en Estadística se encuentra en todos los niveles educativos. En el ámbito universitario siempre hemos tenido como uno de sus ejes más importantes la idea de proporcionar a los estudiantes los conocimientos necesarios para poder contrastar de forma significativa si unas determinadas características de una muestra se pueden generalizar o no a toda la población. En asignaturas de los Estudios de Economía y Empresa de la UOC, la estadística descriptiva, la teoría de la probabilidad, las variables aleatorias y sus funciones de distribución, juegan un papel central, porque precisamente dan las herramientas de trabajo necesarias para la inferencia estadística, para poder hacer contrastes de hipótesis que permitan decir cosas de toda la población cuando no podemos conocer los datos de toda esta población
Quizás en un futuro más o menos próximo este enfoque tendrá que cambiar. Y estas asignaturas deberán orientarse más hacia una realidad donde lo que llamamos Big Data estará ya presente en todos y cada uno de los aspectos de nuestras vidas. Pero hasta entonces, la docencia que estamos haciendo de la Estadística en todas las universidades sigue siendo válida, adecuada, útil y necesaria. Sobre todo útil y necesaria. Y es que en tiempos de incertidumbre, de la COVID-19, el Big Data y la Inteligencia Artificial, la Estadística ha demostrado que sigue siendo eso, útil y necesaria
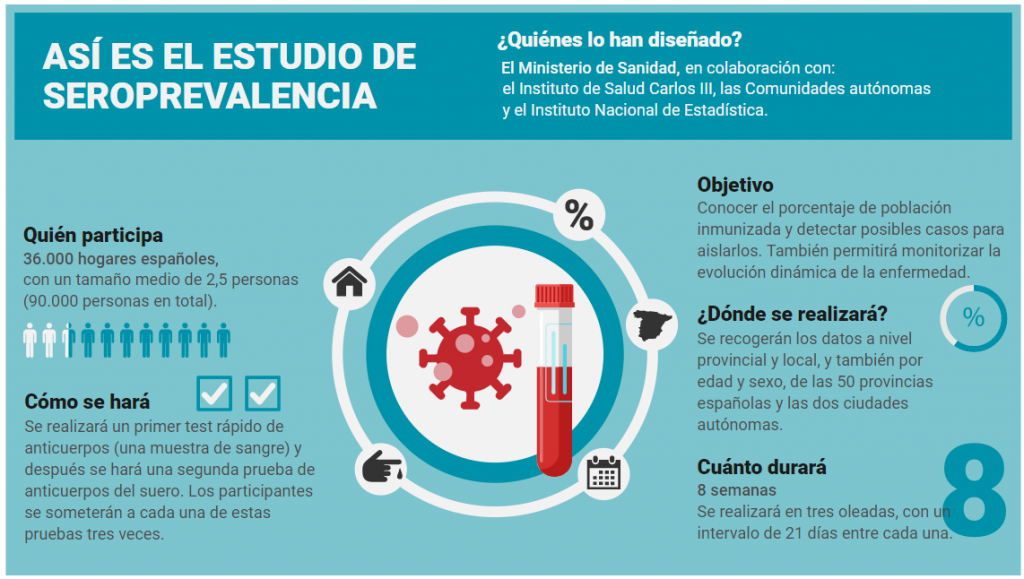
Como ejemplo claro y de gran actualidad, podemos citar el estudio ENECovid19 de prevalencia de la infección por el coronavirus SARS-CoV-2 en la población en España. En este estudio, desarrollado por el Ministerio de Sanidad con la colaboración del Instituto de Salud Carlos III, las Comunidades Autónomas y el Instituto Nacional de Estadística, se pretende saber qué porcentaje de toda la población ha pasado la enfermedad COVID-19, desarrollando anticuerpos, a partir de los resultados obtenidos en una muestra representativa de 36.000 hogares. El informe correspondiente a la primera ronda (de las tres de que consta el estudio), que ha salido estos días, ya aporta de forma preliminar algunas conclusiones muy interesantes, como que la prevalencia en España se sitúa en el cercado del 5% de la población. Resultados como estos, que permiten explicar qué le pasa a toda la población a partir de lo observado en una muestra, ayudarán, sin duda, a comprender mejor la COVID-19, a reducir la incertidumbre, y por tanto a estar más cerca del camino hacia la deseada recuperación económica